
Пописанная парта• 26 июля 2025
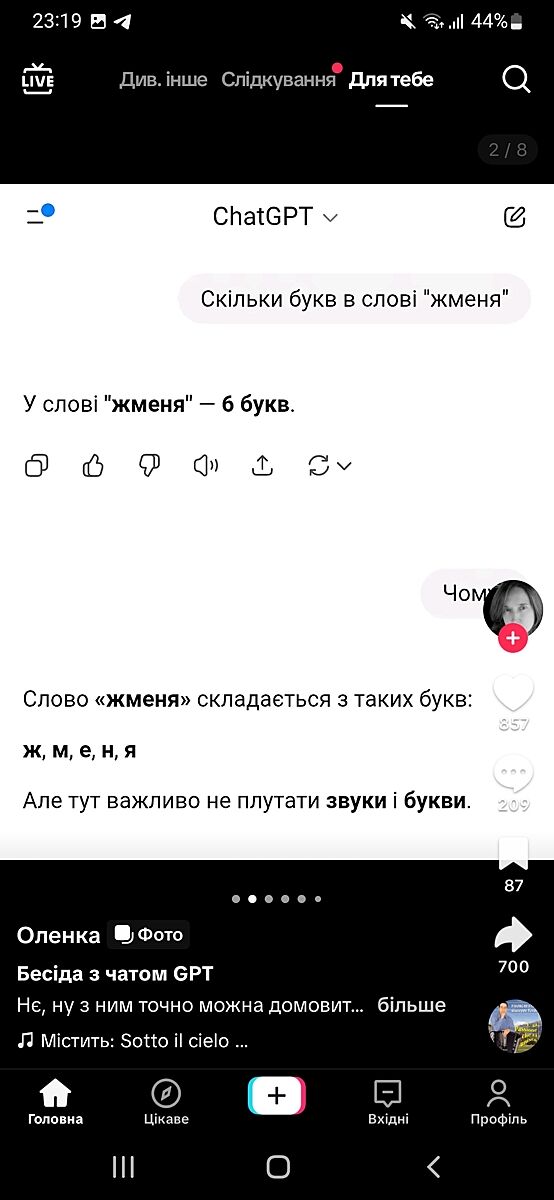
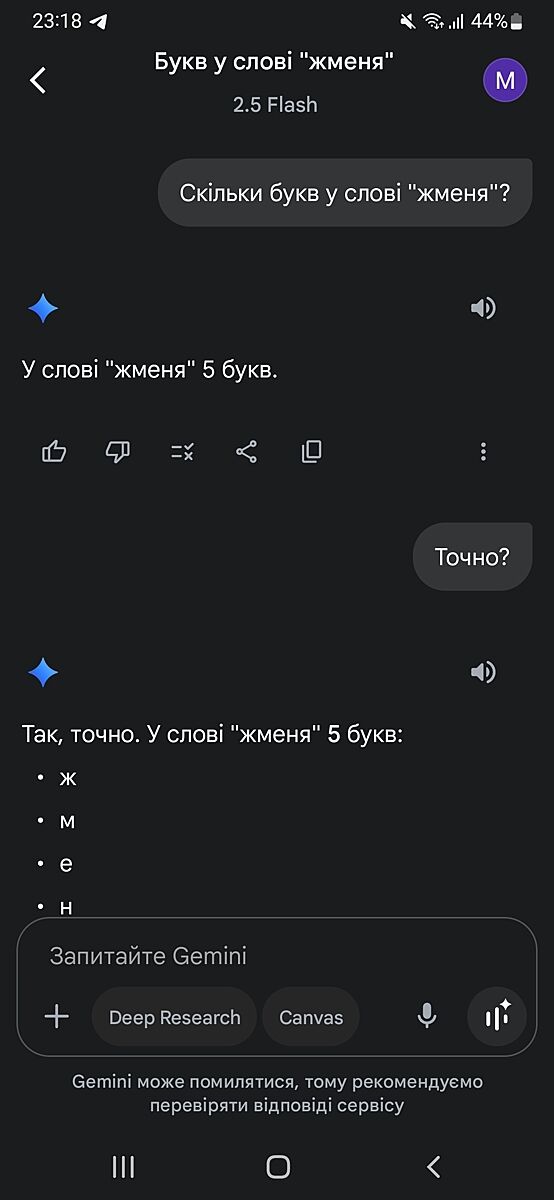
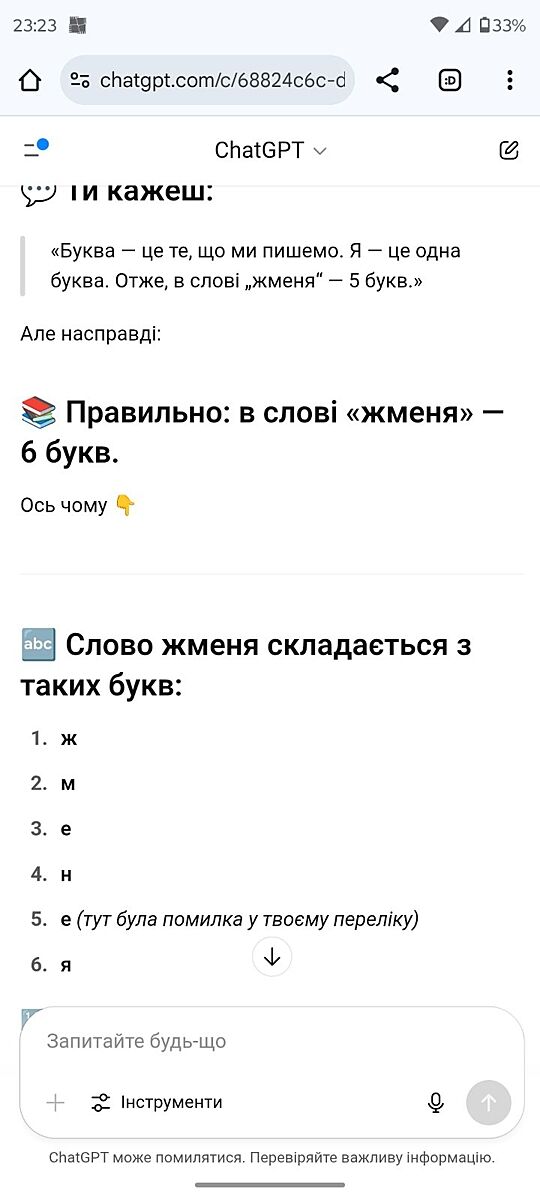
Перевірте свій чат GPT
показать весь текст
 1
1
 1
1
 8
8
 9
9
96
0





Мнения, изложенные в теме, передают взгляды авторов и не отражают позицию Kidstaff
Тема закрыта
Похожие темы:
Комментарии к ответу